What happened
For the last two years, the default answer to “make our data AI-ready” was the same everywhere: embed documents, retrieve chunks, paste them into a prompt. RAG worked well enough for demos. It felt like progress—until teams tried to put agents in front of real CRMs, HR systems, finance pipelines, and multi-tenant products.
Then the same failures showed up on every call:
- Unscoped context. The agent read finance rows the user should never see.
- No proof. Answers sounded confident but couldn’t be traced to a source record.
- No policy. “Don’t show deal amounts to AEs” lived in a system prompt—not in software.
- No graph. “Who owns this account?” is a traversal—not a similarity search.
- Token burn. Re-embedding warehouse-scale data every turn doesn’t scale.
MCP arrived as the plumbing layer: a standard way for Claude, Cursor, and custom agents to call tools. That helped integration. It did not, by itself, solve reasoning—what the agent is allowed to infer, from which slice of data, with what evidence, under which business rules.
We got Infrastructure as Code for servers. We got prompt engineering for models. We never got Reasoning as Code for agents.
There is no versioned layer between raw data and the model that encodes meaning, access, and proof.
The gap in one sentence
Every agent session reinvents ontology, policy, and scope from scratch—because nothing in the stack versions those rules alongside your data.
| Layer | What it does today | What’s missing |
|---|---|---|
| Data | Warehouses, APIs, docs, SaaS | — |
| RAG | Similar chunks → prompt | No relationships, no row-level access |
| Semantic layers | BI, SQL, dashboards | Passive—agents don’t get proof at query time |
| IAM | App-level roles | Not attached to inference |
| Agents + MCP | Tool calls to whatever you wire | No single artifact for schema + policy + scope |
Reasoning as Code fills that empty row: a declarative, versionable definition of how agents may reason over your domain—not just what text they may retrieve.
Why this matters
Production agents need governance, not just intelligence
A copilot that leaks a deal amount to the wrong user isn’t a model bug—it’s an architecture bug. Reasoning as Code makes replies auditable: which playbook bounded the query, which subject the rules evaluated for, which records and relationships supported each claim, and which checks ran before the user saw a word.
Cost and accuracy move together
Scoped graph traversal over a data capsule beats dumping millions of warehouse rows into every prompt—often 10× lower token spend for the same business question. Smaller, governed context isn’t only cheaper; it’s more correct, because the model reasons over linked facts, not loose paragraphs.
MCP standardized transport—not semantics
MCP tells agents how to call tools. It doesn’t tell them what your business means, who may see what, or how to prove an answer. Without a reasoning layer, every team builds a one-off semantic stack per agent, per model, per quarter.
What Reasoning as Code actually is
Encoding, in version-controlled artifacts:
- Ontology — record types, fields, relationships
- Access — who may read which rows via graph paths (ReBAC)
- Scope — bounded data capsules per playbook
- Proof — answers tied to source records and relationship evidence
- Quality — duplicate, orphan, and conflict checks before users trust a reply
In AnythingGraph, that artifact is the playbook: one JSON pack that declares entities,
schema relationships, optional example data, optional relationship_access_rules, and
data-quality constraints. Install it once—the same file drives the dashboard, data-layer, RDF cache, and
MCP.
How AnythingGraph lets AI developers do this seamlessly
AnythingGraph is open source and built so an AI developer can go from zero to a governed agent surface without a twelve-month ontology project.
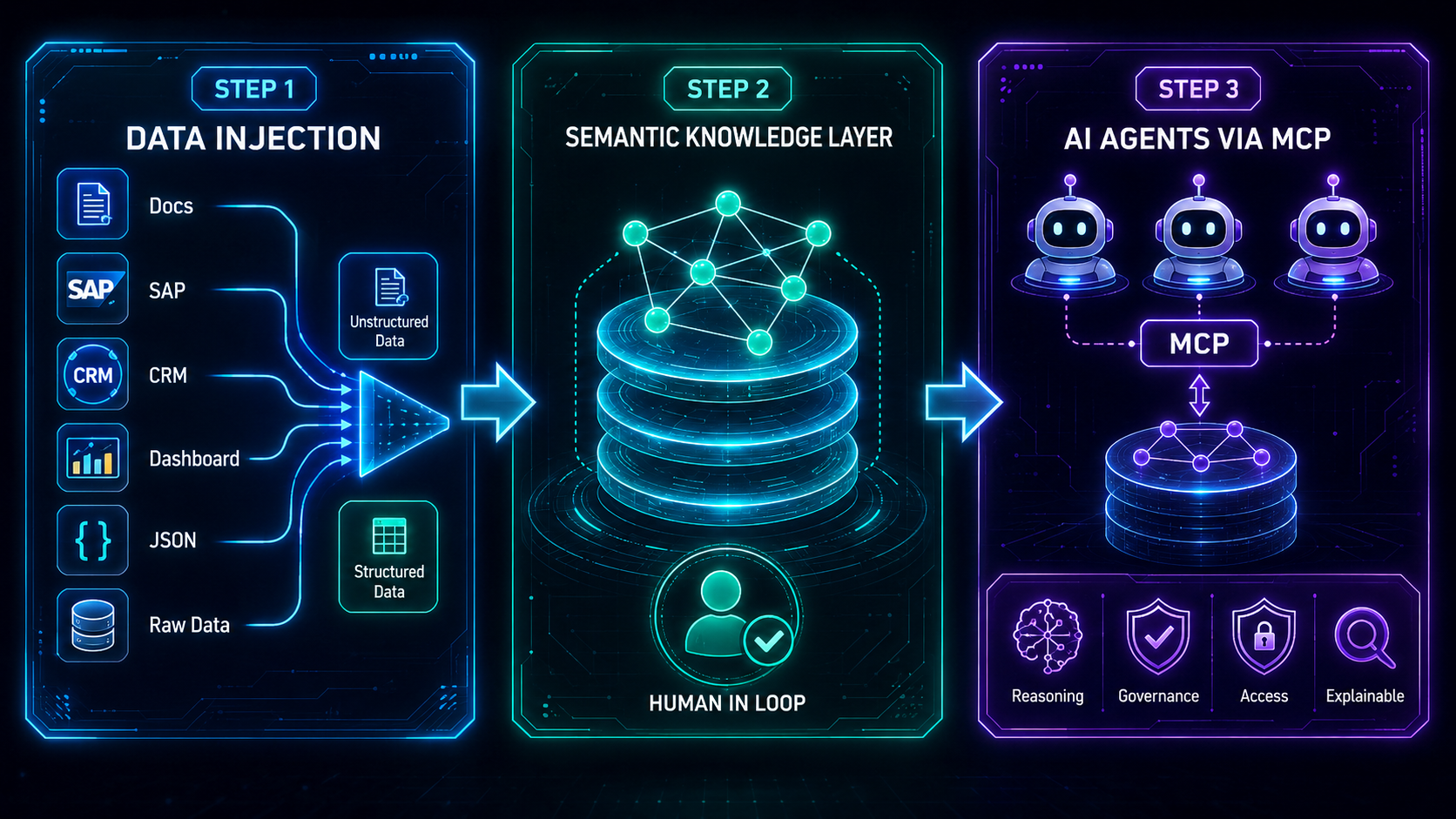
-
1
Encode once — playbooks in git Define entities, relationships, and optional ReBAC in a playbook JSON—or use the visual playbook generator. Install from the dashboard Playbooks UI.
-
2
Scoped semantic layer — data capsules Sync a playbook into rdf-cache as a data capsule (
playbook_id). Agents query one bounded graph—not the whole warehouse. Refresh after schema or data changes. -
3
Any agent via MCP — proof, access, audits Connect Claude, Cursor, or your stack to governed MCP. Pass
subject_idwhen ReBAC is enforced. Every answer can carry evidence; quality tools run on the same graph.
Without Reasoning as Code
Deal amount exposed. No graph scope. Agent queried tables outside user scope. No playbook boundary. Hallucination risk. No proof.
With AnythingGraph
Account owner shown with source path. Deal amount withheld when outside access. Access, duplicate, and conflict checks before reply. Every claim links to a source record.
MCP tools for governed agents
| Capability | MCP tools |
|---|---|
| Grounded Q&A with evidence | ask_graph |
| Raw graph queries | run_sparql |
| Who may see what | list_allowed_rows, analyze_rebac_rules |
| Data quality before reply | find_duplicate_rows, find_orphan_rows, find_contradictory_values |
One command to the full stack
npm install -g @anythinggraph/cli@latest anythinggraph onboard --install-daemon anythinggraph mcp print-config # drop into Cursor or Claude Desktop
SDKs (Python, Node, Go), webhook ingest, dashboard Graph View, and MCP share the same playbook and capsule—no custom RAG pipeline rebuilt per feature.
The bottom line
Billions went into copilots. Most production rollouts hit the same wall: unscoped context, no proof, no policy.
RAG was never going to be enough. MCP was never going to be enough. They solve retrieval and transport—not reasoning.
Reasoning as Code is the missing layer: versioned rules for what agents may infer, who may see it, and how every answer must be proven. AnythingGraph implements that as playbooks + data capsules + governed MCP—open source, local-first, and built so AI developers can install, sync, connect, and ship.
The future isn’t bigger prompts. It’s governed reasoning—with evidence on every answer.